分布式数据分析是什么,什么是分布式数据分析?
浏览量: 次 发布日期:2024-11-21 10:04:37
什么是分布式数据分析?

分布式数据分析是一种利用分布式计算技术对大规模数据集进行高效处理和分析的方法。随着互联网和物联网的快速发展,数据量呈爆炸式增长,传统的集中式数据分析方法已经无法满足日益增长的数据处理需求。分布式数据分析通过将数据分散存储在多个节点上,并利用这些节点进行并行计算,从而实现对海量数据的快速分析和处理。
分布式数据分析的优势
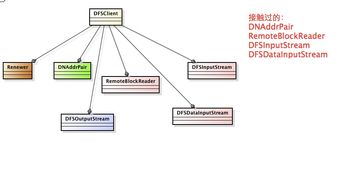
分布式数据分析具有以下优势:
高效率:通过并行计算,分布式数据分析可以显著提高数据处理速度,缩短分析周期。
高扩展性:分布式系统可以根据需要动态扩展,适应不断增长的数据量。
高可靠性:分布式系统具有容错能力,即使部分节点出现故障,也不会影响整体系统的正常运行。
低成本:分布式数据分析可以利用现有的硬件资源,降低数据分析成本。
分布式数据分析的关键技术
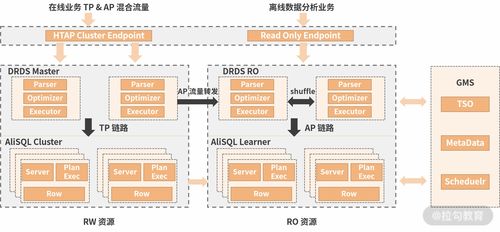
分布式数据分析涉及多种关键技术,以下列举其中一些:
分布式文件系统:如Hadoop的HDFS(Hadoop Disribued File Sysem),用于存储海量数据。
分布式计算框架:如MapReduce、Spark等,用于并行处理数据。
数据分区与负载均衡:将数据均匀分配到各个节点,提高数据处理效率。
数据同步与一致性:确保数据在不同节点之间的一致性。
数据挖掘与机器学习算法:用于从海量数据中提取有价值的信息。
分布式数据分析的应用场景
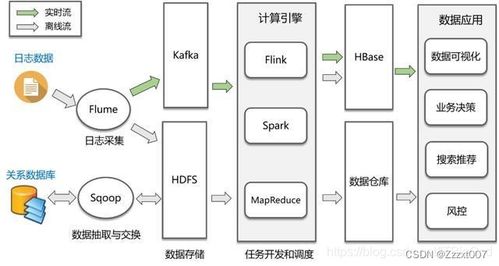
分布式数据分析在各个领域都有广泛的应用,以下列举一些典型应用场景:
互联网和电子商务平台:通过分析用户行为数据,优化产品推荐、广告投放等。
金融服务:对交易数据进行实时监控和分析,防范风险。
物联网:分析设备运行数据,实现设备故障预测和维护。
大数据分析:从海量数据中挖掘有价值的信息,为决策提供支持。
实时高并发事务系统:处理大规模并发请求,保证系统稳定运行。
分布式数据分析的未来发展趋势
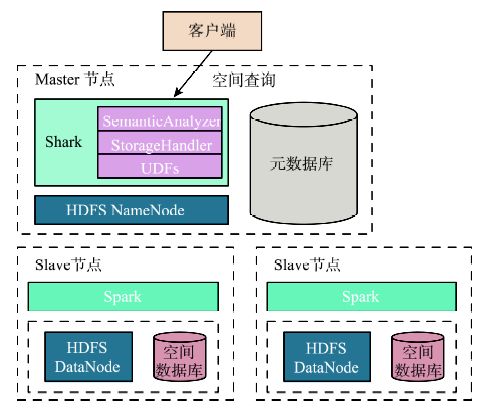
随着技术的不断进步,分布式数据分析在未来将呈现以下发展趋势:
水平扩展与自动化管理:分布式系统将更加注重水平扩展,并实现自动化管理,降低运维成本。
一致性与可用性权衡:在保证数据一致性的同时,提高系统的可用性。
多模型支持与多租户隔离:支持多种数据模型,满足不同业务需求;实现多租户隔离,提高系统安全性。

分布式数据分析作为一种高效、可靠的数据处理方法,在各个领域都发挥着重要作用。随着技术的不断发展,分布式数据分析将在未来得到更广泛的应用,为各行各业带来更多价值。





 QQ客服
QQ客服