分布式数据源有哪些
浏览量: 次 发布日期:2024-11-30 09:29:30
分布式数据源:构建高效数据处理的基石 引言在当今大数据时代,分布式数据源已成为企业构建高效数据处理平台的关键。本文将深入探讨分布式数据源的概念、优势、常见架构以及在实际应用中的挑战和解决方案。 分布式数据源概述 什么是分布式数据源?
标签
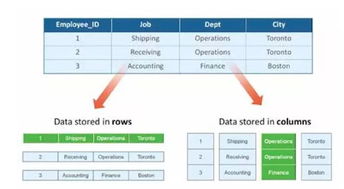
分布式数据源是指将数据分散存储在多个节点上,通过分布式计算框架进行数据处理的系统。它能够有效提高数据处理的性能、扩展性和容错性。
分布式数据源的优势标签
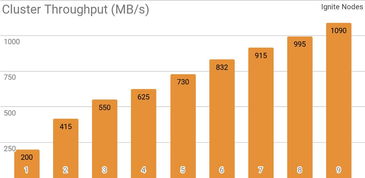
1. 高性能:分布式数据源能够并行处理数据,显著提高数据处理速度。
2. 高扩展性:随着数据量的增长,分布式数据源可以轻松扩展,满足不断增长的数据处理需求。
3. 高可用性:分布式数据源通过数据冗余和故障转移机制,确保系统的高可用性。
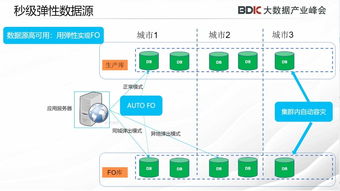
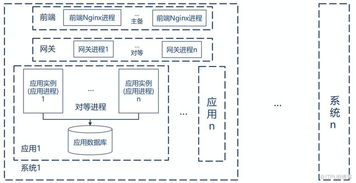
常见分布式数据源架构 分布式数据库标签
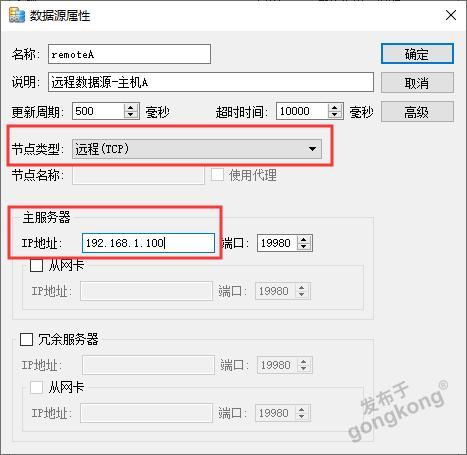
分布式数据库如Apache Cassadra、Amazo DyamoDB等,通过数据分片和复制机制实现数据的分布式存储。
分布式文件系统标签
分布式文件系统如Hadoop HDFS、Alluxio等,提供大规模数据存储和访问能力。
分布式计算框架标签
分布式计算框架如Apache Spark、Apache Flik等,支持批处理、流处理和实时计算。
分布式数据源在实际应用中的挑战 数据一致性问题标签
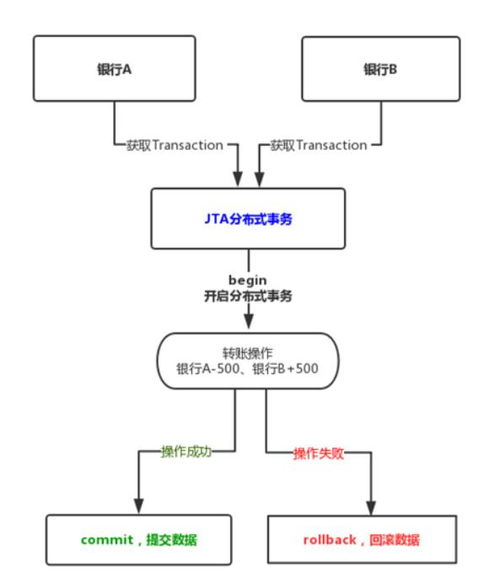
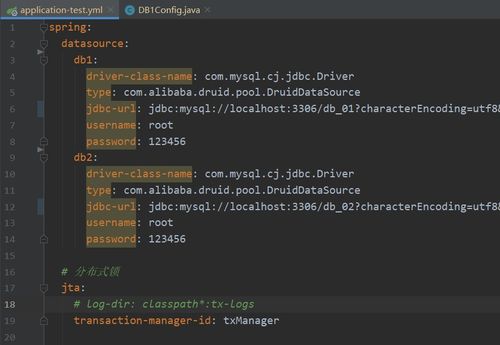
在分布式数据源中,数据一致性问题是一个常见挑战。需要采用分布式锁、事务管理等机制来保证数据一致性。
数据分区和负载均衡标签
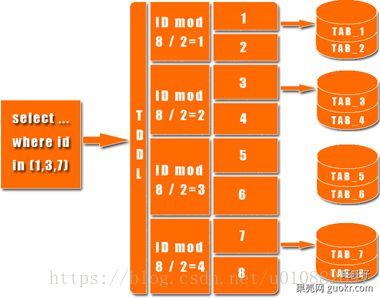
数据分区和负载均衡是分布式数据源的关键技术。合理的数据分区和负载均衡策略能够提高系统性能和可扩展性。
容错和故障转移标签
分布式数据源需要具备容错和故障转移能力,以应对节点故障和数据丢失等问题。
解决方案与最佳实践 分布式锁标签
分布式锁可以保证在分布式环境中对共享资源的访问互斥性。常见的分布式锁实现包括基于Zookeeper、Redis等。
数据分区策略标签
合理的数据分区策略能够提高数据处理的并行度和系统性能。常见的分区策略包括范围分区、哈希分区等。
负载均衡标签
负载均衡技术可以将请求均匀分配到各个节点,提高系统吞吐量和可用性。常见的负载均衡算法包括轮询、最少连接数等。
分布式数据源在提高数据处理性能、扩展性和可用性方面发挥着重要作用。通过深入了解分布式数据源的概念、架构和挑战,企业可以构建高效、可靠的数据处理平台,满足日益增长的数据处理需求。 关键词分布式数据源、分布式数据库、分布式文件系统、分布式计算框架、数据一致性、数据分区、负载均衡、容错、故障转移
相关推荐





 QQ客服
QQ客服