分布式数据服务,构建高效、可靠的跨设备数据协同
浏览量: 次 发布日期:2024-12-02 10:00:56
深入解析分布式数据服务:构建高效、可靠的跨设备数据协同

随着物联网、云计算等技术的快速发展,分布式数据服务在各个行业中扮演着越来越重要的角色。本文将深入解析分布式数据服务的概念、特点、应用场景以及开发步骤,帮助读者全面了解这一技术。
标签:分布式数据服务,概述

分布式数据服务(Disribued Daa Service,简称DDS)是一种基于分布式架构的数据存储和访问技术。它允许应用程序在不同的设备、不同的地理位置上共享和同步数据,从而实现跨设备的数据协同。DDS的核心优势在于其高可用性、高可靠性和易扩展性。
标签:分布式数据服务,特点
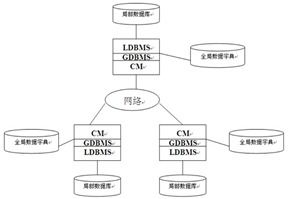
分布式数据服务具有以下特点:
高可用性:通过分布式存储和备份机制,确保数据在设备故障或网络中断的情况下仍然可用。
高可靠性:采用多副本存储和一致性算法,保证数据的一致性和准确性。
易扩展性:支持水平扩展,可根据需求增加存储节点,提高系统性能。
跨设备协同:支持不同设备间的数据共享和同步,实现跨设备的数据访问。
标签:分布式数据服务,应用场景

分布式数据服务在以下场景中具有广泛的应用:
物联网:实现设备间的数据共享和同步,如智能家居、智能城市等。
云计算:提供云存储和云数据库服务,满足大规模数据存储和访问需求。
移动应用:实现跨设备的数据同步,如跨平台应用、移动办公等。
社交网络:实现用户数据的跨设备同步,如社交圈、朋友圈等。
标签:分布式数据服务,开发步骤

以下是开发分布式数据服务的步骤:
导入模块:在项目中引入分布式数据服务的相关模块。
构造分布式数据库管理类实例:创建分布式数据库管理类的实例,用于管理分布式数据库。
获取、创建分布式数据库:根据需求获取或创建分布式数据库。
订阅分布式数据库的数据变化:监听分布式数据库的数据变化,实现实时数据同步。
插入数据到分布式数据库:将数据插入到分布式数据库中。
查询分布式数据库数据:从分布式数据库中查询数据。
删除分布式数据库数据:从分布式数据库中删除数据。
标签:分布式数据服务,数据模型

分布式数据服务的数据模型通常采用键值对(KV)模型,即数据以键值对的形式进行组织、索引和存储。这种模型简单易用,适用于存储结构化数据和非结构化数据。
标签:分布式数据服务,约束和限制

在使用分布式数据服务时,需要注意以下约束和限制:
数据模型:仅支持KV模型,不支持外键、触发器等关系数据库中的功能。
设备协同数据库:针对每条记录,Key的长度限制为896 Bye。
权限限制:应用程序如需使用分布式数据服务完整功能,需要申请ohos.permissio.DISTRIBUTEDDATASYC权限。
标签:分布式数据服务,

分布式数据服务作为一种高效、可靠的跨设备数据协同技术,在各个行业中具有广泛的应用前景。通过本文的介绍,相信读者对分布式数据服务有了更深入的了解。在实际应用中,开发者可以根据需求选择合适的分布式数据服务,实现跨设备的数据共享和同步,为用户提供更好的服务体验。





 QQ客服
QQ客服