数据结构范式,数据结构范式的概述
浏览量: 次 发布日期:2024-11-03 02:18:29
数据结构范式的概述
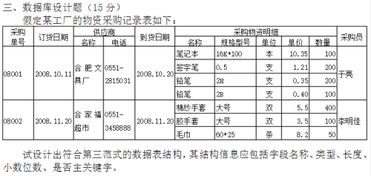
数据结构范式是数据库设计中用来规范数据组织方式的一系列规则。通过遵循这些规则,可以确保数据库中的数据既高效又一致。数据结构范式主要应用于关系型数据库,其目的是减少数据冗余、避免数据不一致,并提高查询效率。
第一范式(1F)

第一范式(1F)是关系数据库设计的基础。它要求关系中的每个属性都是不可分割的原子值,即每个字段只能包含一个值。1F的目的是消除重复组,确保每行数据都是唯一的。
例如,一个学生信息表,如果包含学生的姓名、学号、班级和班级名称,那么班级名称应该单独作为一个字段,而不是作为班级字段的一部分。这样可以确保每个字段都是原子性的,满足1F的要求。
第二范式(2F)
第二范式(2F)在1F的基础上,要求关系中的所有非主属性都完全依赖于主键。这意味着非主属性不能依赖于主键的任何部分,而必须依赖于整个主键。
例如,一个订单表,如果包含订单编号、客户名称、客户地址和订单详情,那么客户名称和地址应该放在一个单独的客户表中,而不是作为订单表的一部分。这样可以避免数据冗余,并确保非主属性完全依赖于主键。
第三范式(3F)
第三范式(3F)在2F的基础上,进一步要求关系中的所有非主属性不仅完全依赖于主键,还不能传递依赖于主键。这意味着非主属性不能依赖于其他非主属性。
例如,一个员工表,如果包含员工编号、部门编号、部门名称和员工姓名,那么部门名称应该放在一个单独的部门表中,而不是作为员工表的一部分。这样可以避免数据冗余,并确保非主属性不传递依赖于主键。
BCF(Boyce-Codd范式)

BCF是第三范式的进一步扩展,它要求关系中的每个决定因素都必须是候选键。这意味着在BCF中,不存在非主属性对候选键的部分依赖或传递依赖。
例如,如果一个关系中的某个非主属性对候选键的部分依赖或传递依赖,那么需要进一步分解关系,直到满足BCF的要求。
第四范式(4F)和第五范式(5F)
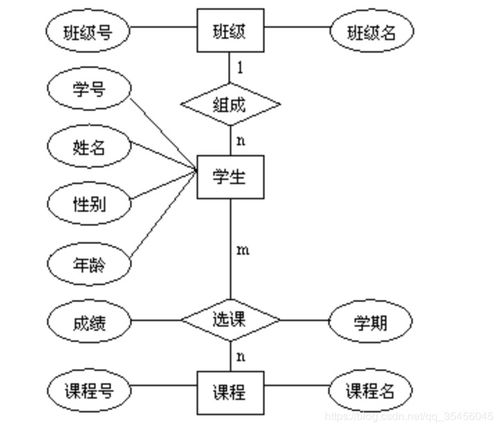
第四范式(4F)和第五范式(5F)是更高层次的范式,它们用于解决更复杂的数据依赖问题。
4F解决多值依赖问题,即一个属性组可以决定多个候选键。5F解决连接依赖问题,即一个属性组可以决定另一个属性组,而后者不是候选键。
数据结构范式是数据库设计中非常重要的概念,它们有助于确保数据库中的数据既高效又一致。通过遵循不同的范式,可以减少数据冗余、避免数据不一致,并提高查询效率。在实际应用中,应根据具体需求选择合适的范式,以优化数据库设计。





 QQ客服
QQ客服